There are several tools for migrating VMWare VM’s to Hyper-V. The free tool from Microsoft is called the Microsoft Virtual Machine Converter which allows you to convert from VMWare to Hyper-V or Azure, and from physical to virtual via a GUI or powershell cmdlets for automation. Microsoft also has the Migration Automation Toolkit which can help automate this process. If you have NetApp, definitely check out MAT4SHIFT which is by far the fastest and easiest method for converting VMWare VM’s to Hyper-V. MVMC works fairly well, however, there are a few things the tool doesn’t handle natively when converting from VMWare to Hyper-V.
First, it requires credentials to the guest VM to remove the VMWare Tools. In a service provider environment, you may not have access to the guest OS, so this could be an issue. Second, the migration will inherently cause a change in hardware, which in turn can cause the guest OS to lose its network configuration. This script accounts for that by pulling the network configuration from the guest registry and restoring it after the migration. Lastly, MVMC may slightly alter other hardware specifications (dynamic memory, mac address) and this script aims to keep them as close as possible with the exception of disk configuration due to Gen 1 limitations in Hyper-V booting.
This script relies on several 3rd party components:
- Microsoft Virtual Machine Coverter 3.0
- Hyper-V Module for Powershell
- VMWare PowerCLI 5.8
- Devcon.exe from the Windows Driver Kit 8.1
- Integration Services ISO from Hyper-V host
- VMWare Tools ISO from ESXi host
- Non-sucking Service Manager
- The VMWare to Hyper-V Converter script
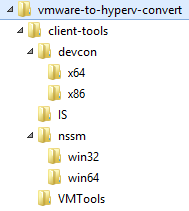
You’ll need to install MVMC, HV PS Module, and VMWare PowerCLI on your “helper” server – the server where you’ll be running this script which will perform the conversion. Devcon, the HV IS components, VMWare Tools, and NSSM will need to be extracted into the appropriate folders:
I’ve included a sample kick-off script (migrate.ps1) that will perform a migration:
$esxhost = "192.168.0.10" $username = "root" $password = ConvertTo-SecureString "p@ssWord1" -AsPlainText -Force $cred = New-Object -Typename System.Management.Automation.PSCredential -Argumentlist "root", $password $viserver = @{Server=$esxhost;Credential=$cred} $destloc = "\\sofs.contoso.int\vm-storage1" $vmhost = "HV03" $vmname = "MYSERVER01" cd C:\vmware-to-hyperv-convert . .\vmware-to-hyperv.ps1 -viserver $viserver -VMHost $vmhost -destLoc $destloc -VerboseMode $vms = VMware.VimAutomation.Core\Get-VM -Server $script:viconnection $vmwarevm = $vms | ?{$_.Name -eq $vmname} $vm = Get-VMDetails $vmwarevm Migrate-VMWareVM $vm |
Several notes about MVMC and these scripts:
- This is an offline migration – the VM will be unavailable during the migration. The total amount of downtime depends on the size of the VMDK(s) to be migrated.
- The script will only migrate a single server. You could wrap this into powershell tasks to migrate several servers simultaneously.
- Hyper-V Gen1 servers only support booting from IDE. This script will search for the boot disk and attach it to IDE0, all other disks will be attached to a SCSI controller regardless of the source VM disk configuration.
- Linux VM’s were not in scope as there are not reliable ways to gain write access to LVM volumes on Windows. Tests of CentOS6, Ubuntu12 and Ubuntu14 were successful. CentOS5 required IS components be pre-installed and modifications made to boot configuration. CentOS7 was unsuccessful due to disk configuration. The recommended way of migrating Linux VM’s is to pre-install IS, remove VMWare Tools, and modify boot configuration before migrating.
- These scripts were tested running from a Server 2012 R2 VM migrating Server 2003 and Server 2012 R2 VM’s – other versions should work but have not been tested.
- ESXi 5.5+ requires a connection to a vCenter server as storage SDK service is unavailable on the free version.
")



