Dell introduced a feature in their 11G servers called demand-based power management (DBPM). Other platforms refer to this feature as “power management” or “power policy” whereby the system adjusts power used by various system components like CPU, RAM, and fans. In today’s green-pc world, it’s a nice idea, but the reality with cloud-based environments is that we are already consolidating systems to fewer physical machines to increase density and power policies often interfere with the resulting performance.
We recently began seeing higher than normal READY times on our VM’s. Ready time refers to the amount of time a process needed CPU time, but had to wait because no processors were available. In the case of virtualization, this means a VM had some work to do, but it could not find sufficient free physical cores that matched the number of vCPU’s assigned to the VM. VMWare has a decent guide for troubleshooting VM performance issues which led to some interesting analysis. Specifically, our overall CPU usage was only around 50%, but some VM’s were seeing ready times of more than 20%.
This high CPU ready with low CPU utilization could be due to several factors. Most commonly in cloud environments, it suggests the ratio of vCPU’s (virtual CPU’s) to pCPU’s (physical CPU’s) is too high, or that you’ve sized your VM’s improperly with too many vCPU’s. One important thing to understand with virtual environments, is that a VM with multiple cores needs to wait for that number of cores to become free across the system. Assuming you have a single host with 4 cores running 4 VM’s, 3 VM’s with 1vCPU and 1 VM with 4vCPU’s, the 3 single vCPU VM’s could be scheduled to run concurrently while the fourth would have to wait for all pCPU’s to become idle.
Naturally, the easiest way to fix this is to add additional physical CPU’s into the fold. We accomplished this by upgrading all of our E5620 processors (4-core) in our ESXi hosts to E5645 processors (6-core) thereby adding 28 additional cores to the platform. However, this did not help with CPU READY times. vSphere DRS was still reporting trouble delivering CPU resources to VM’s:
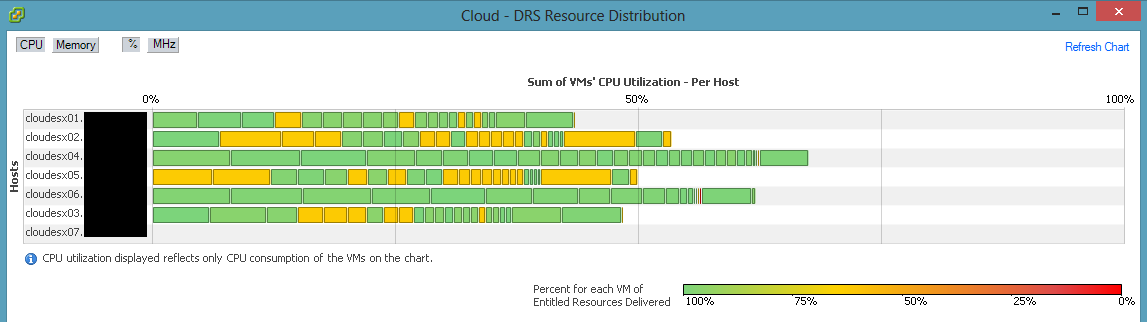
After many hours of troubleshooting, we were finally about to find a solution – disabling DBPM. One of the hosts consistently showed lower CPU ready times even though it had higher density. We were able to find that this node had a different hardware power management policy than the other nodes. You can read more about what this setting does in the Host Power Management whitepaper from VMWare. By default, this policy is automatically set as a result of ACPI CPU C-States, Intel Speedstep and the hardware’s power management settings on the system.
On our Dell Poweredge R610 host systems, the DBPM setting was under Power Management in the BIOS. Once we changed all systems from Active Power Controller to Maximum Performance, CPU ready times dropped to normal levels.
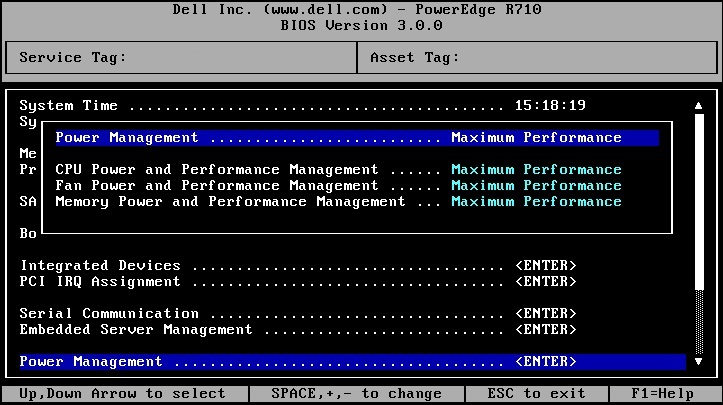
Information on the various options can be found in this Power and Cooling wiki from Dell. Before settling on this solution, we attempted disabling C-States altogether and C1E specifically in the BIOS, but neither had an impact. We found that we could also specify OS Control for this setting to allow vSphere to set the policy, though we ultimately decided that Maximum Performance was the best setting for our environment. Note that this isn’t specific to vSphere – the power management setting applies equally to all virtualization platforms.
")



